不小心錯過 12:00,12:10才送出,今年參賽又中斷了 T.T
前一篇,我們為了避免 GPT 返還的文字不夠精確,使用正則表達式(Regex) 檢查並提取「商品檢驗標識」及「批號」資訊,接著,就要用兩者作為條件,對政府公開網站進行爬蟲,並把查詢結果回傳給前端。
1. 爬蟲方法的選擇
在設計這套系統之前,先要決定「要用什麼方式抓資料」。常見的三種方法是:
(1) Requests
(2) Pyppeteer
(3) Selenium
總結:
👉 靜態頁面或 API → 用 requests
👉 動態頁面且需模擬操作 → 用 Pyppeteer / Selenium
2. 為什麼選用 requests 的方式?
原因是我們爬蟲的標的網站,不用模擬點擊或等待 JavaScript,只要正確帶入參數,伺服器就會回傳 JSON。
這種情況下得最佳選擇就是 requests,避免了 Selenium、Pyppeteer 「開瀏覽器」的額外負擔。
3. 查詢邏輯說明
我們設計了一個 CertSearch 類別,負責處理 M、R、D 三種字軌。
程式碼中透過使用 config 字典,集中管理不同字軌的 API URL、參數生成器、解析方法。
以下用 M 字軌來示範,如前一篇所述,M 字軌這種檢驗方式需要進一步搜尋「批號」,才能得到查驗紀錄。
實際上需要給予 API URL什麼參數,可以透過以下方法推導:
(1) 觀察官方網頁表單
進到標的網頁的「查詢頁面」,按下 F12 開啟「開發者工具」。
在「網路 (Network)」頁籤中,嘗試輸入字軌與批號後按下查詢,看看瀏覽器送出的 Request Payload 或 Form Data。就能看到請求中帶了哪些欄位名稱 (例如 q_regType、q_regNo 等)。
(2) 可能會需要試錯驗證
一開始可能只傳 q_regNo,發現 API 回傳不完整。
再逐步補上 q_regType、q_madeNo 等欄位,直到回傳正確結果。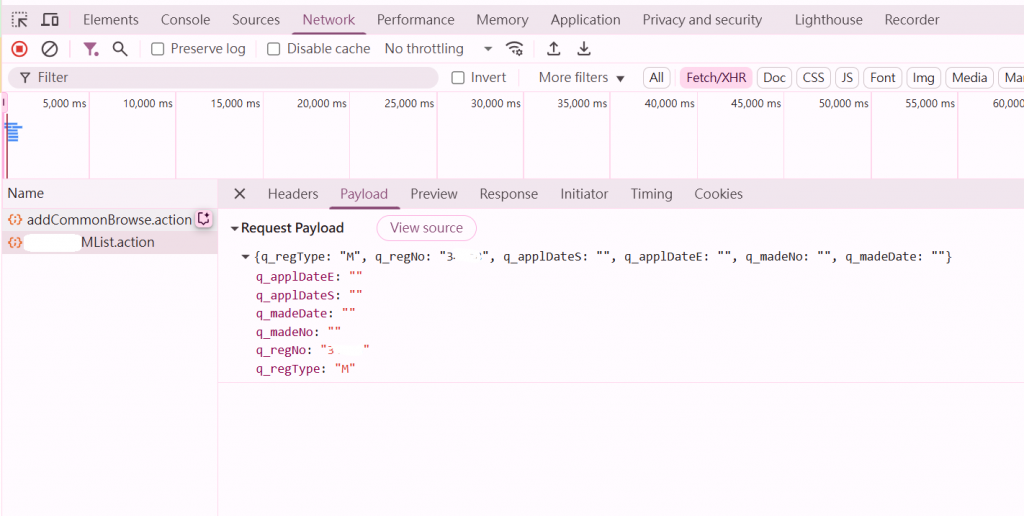
//app.py
import requests
class CertSearch:
def __init__(self):
self.config = {
"M": {
//從「網路 (Network)」下 Header 頁籤中的 Request URL,可以發現 M 字軌的爬蟲標的網址是 https://civil.bsmi.gov.tw/bsmi_pqn/API/00000MList.action(網址有經過處理,但有心還是找的到)
"url": "https://civil.bsmi.gov.tw/bsmi_pqn/API/00000MList.action",
"params": lambda MRD_num, batch_num: {
"q_regType": MRD_num[0],
"q_regNo": MRD_num[-5:],
"q_madeNo": batch_num if batch_num else None,
"q_applDateE":"",
"q_applDateS":"",
"q_madeDate":""
},
"parser": self.parse_response_M
},
"R": {
...(略)...
}
}
接著,定義 Header。
HTTP Header 是網路傳輸中請求與回應的「說明文件」,負責告訴伺服器或瀏覽器這份資料的「背景資訊」,例如資料型態 (Content-Type)、來源 (Referer)、使用者環境 (User-Agent)、登入狀態 (Cookie)。
沒有 Header,伺服器可能無法判斷該怎麼處理資料,也可能被拒絕存取,因此 Header 是網頁正確溝通與驗證的重要依據。每台設備的 header 略有不同,可以用網站查詢自己的某台設備爬蟲時應該使用什麼 header。又標的網站需要背景資訊中的哪些資訊也可能略有不同,會需要依照實際情況調整。
//延續class CertSearch:...
# Headers
self.headers = {
"Content-Type": "application/json",
"User-Agent": ".....",
"Cookie": ".....",
"Accept": ".....",
"Accept-Encoding": ".....",
"Connection": ".....",
"Host": ".....",
"Referer": ".....",
"Origin": "....."
}
再來是爬蟲查詢的核心方法 search() 。這裡有幾個重點:
(1) 自動重試:@retry 失敗時會重新嘗試。
(2) 快取:@lru_cache 避免重複查詢同一個字號。
(3) 錯誤處理:遇到非 200 狀態碼,會直接提示「爬取失敗」。
(4) 為什麼使用 POST 方法爬蟲?
POST 方法能把查詢條件放在請求 body,比 GET 更適合傳送較多或敏感資料,同時從「網路 (Network)」下 Header 頁籤中的 Request Method,可以發現伺服器 API 的設計需求(如下圖)。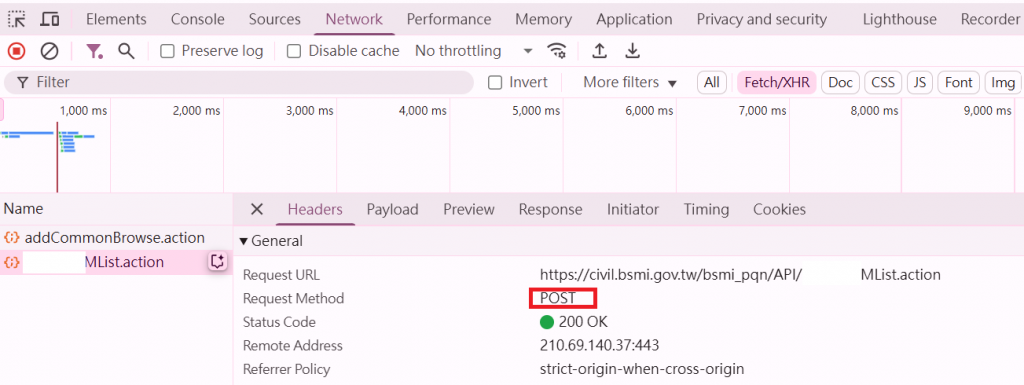
//延續class CertSearch:...
@retry(stop=stop_after_attempt(3), wait=wait_fixed(2))
@lru_cache(maxsize=100)
def search(self, bsmiNum, batchNum):
"""
根據 bsmiNum 的首字母決定 URL 和參數,並發送查詢請求。
"""
//爬蟲返還結果的儲存容器
return_message = ""
//取檢驗字號中取出字軌是 M, R 或是 D
query_type = bsmiNum[0]
if query_type not in self.config:
return "查無此字軌"
//設定對應的 URL、參數以及返回條件
url = self.config[query_type]["url"]
params_generator = self.config[query_type]["params"]
parser = self.config[query_type]["parser"]
//生成參數
params = params_generator(bsmiNum, batchNum)
//因為是POST 請求
try:
response = requests.post(url, json=params, headers=self.headers)
//當狀態碼不是 200-299時啟動
response.raise_for_status()
except requests.exceptions.RequestException as e:
return f"爬取失敗:{e}"
# return_message
//要返回前端文字框的結果
return_message = parser(response)
return return_message
最後,我們還要處理爬蟲返還的文字,以下一樣以 M 字軌為例,結果會顯示廠商資訊+每筆報驗紀錄。
至於,如何知道返還的資料中哪些欄位是我們需要的,可以先使用 print(parsed_data) 出來看。
//延續class CertSearch:...
//處理M字軌返回結果
def parse_response_M(self, response):
try:
parsed_data = response.json()
# 提取需要的資訊作為狀況篩選條件
data_reg_no = parsed_data.get('dataRegNo')
data_appl_name = parsed_data.get('dataApplName')
records = parsed_data.get('data')
# 情況一: 無此m字軌
if data_reg_no is None:
return "查無此M批號"
# 情況二: 有字軌,無報驗紀錄
if not records:
return (
f"廠商資訊如下:\n"
f"自印標識號碼 : {data_reg_no}\n"
f"申請人 : {data_appl_name}\n無報驗紀錄"
) if data_appl_name else "無報驗紀錄"
records_info = "\n".join(
f"報驗案號:{record.get('L0', '')}\n"
f"製造批號:{record.get('L1', '')}\n"
f"報驗日期:{record.get('L2', '')}\n"
f"檢驗結果:{record.get('L3', '')}\n-------------------------"
for record in records
)
if not records_info.strip():
return "查無報驗紀錄"
return (
f"廠商資訊如下:\n自印標識號碼 : {data_reg_no} \n申請人 : {data_appl_name}\n\n"
f"-------------------------\n報驗紀錄如下:\n-------------------------\n{records_info}"
)
except (ValueError, KeyError) as e:
return f"錯誤:{str(e)}"
searcher = CertSearch()
4. 後端邏輯說明
在這之間,我們會透過 Flask 提供的 /cert 路由,讓前端把 OCR 結果送來,後端再進行查詢,並把結果回傳 JSON。
Flask 路由就像網頁的「門牌號碼」,告訴後端哪個網址對應哪段程式邏輯。也就是說,
(1) 前端透過 Flask 的 /cert 路由,把 OCR 文字傳到後端。
(2) 後端從文字中抓到字號與批號,呼叫 searcher.search(bsmiNum, batchNum)。
(3) search 方法判斷字軌為 "M",就會呼叫對應的 parser,也就是 parse_response_M(response),把 API 回傳的 JSON 解析成可讀文字。
(4) 解析後的文字(如廠商資訊、報驗紀錄)會存入 return_message,然後由 Flask 再回傳給前端。前端看到的查詢結果文字就是 parse_response_M 處理後的內容。
@app.route('/cert', methods=['POST'])
def cert():
try:
//接收「前端」發送的資料
ocrText = request.files['ocrText'].read().decode('utf-8')
//取字軌和批號
bsmiNum, batchNum = find_bsmiNum_and_batchNum(ocrText)
//根據 MRD_num 和 batch_num 呼叫 search
result = searcher.search(bsmiNum, batchNum)
//將處理後的結果送回「前端」
return jsonify({
'bsmiNum': bsmiNum,
'batchNum': batchNum,
'result': result
})
//錯誤處理
except KeyError as e:
return f"KeyError: {e} not found in form data", 400
except Exception as e:
return f"Error: {str(e)}", 500
爬蟲是一個很有趣的技術,透過自動化流程,我們可以快速抓取所需資料,提升工作效率。又在未能取得公開 API的情況下,比起常常設有大量 JavaScript 動態載入、登入驗證、頁面分頁、API 加密或反爬蟲機制的(購物)網站,公家單位的網站就個人經驗是很好的練習標的,有的甚至用 get 方法就能取得資料。
希望這篇文能幫助到正在學習爬蟲的人。

